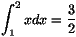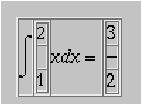4 Reconnaissance de LATEX
Cette section détaille l'analyseur principal de HEVEA.
4.1 Unité lexicales élémentaires
Chaque unité lexicale reconnue entraînera une action, émission de HTML ou
modification de l'état interne du traducteur.
La reconnaissance des unité lexicales n'offre aucune difficulté
particulière si on utilise ocamllex : il suffit d'identifier
les expressions régulières qui les décrivent.
La lecture répétitive du flot d'entrée lexbuf est assurée par
des appels récursifs à l'entrée principale main de
l'analyseur lexical ou à d'autres entrées.
Voici par exemple la reconnaissance des commentaires.
rule main = parse
'%' {comment lexbuf}
:
and rule comment = parse
'\n' {main lexbuf}
| _ {comment lexbuf}
L'action réalisée ici est extrêmement simple : le contenu d'un
commentaire est ignoré.
On remarquera la présence du flot d'entrée lexbuf
comme argument explicite des entrées de l'analyseur.
Considérons ensuite l'analyse de quelques éléments lexicaux
particuliers.
On se limitera dans un premier temps, aux éléments lexicaux constitués
d'un seul caractère, par souci de simplicité.
Un certain nombre de caractères sont actifs en LATEX,
ce sont par exemple
les caractères de début et de fin de groupe ``{''
et ``}'' :
| '{' {Html.open_block "" "" ; main lexbuf}
| '}' {Html.close_block "" ; main lexbuf}
L'action réalisée est l'ouverture et la fermeture d'un bloc par le
gestionnaire de sortie.
Il s'agit d'une simplification comme on le
verra à la section suivante.
Notons que,
pour vérifier le bon parenthésage
des ouvertures et fermetures de groupes, on peut, pour le moment,
s'en remettre à la pile des blocs du gestionnaire de sortie.
Voici ensuite quelques exemple de sortie de caractères, les caractères
qui ``<'' et ``>'' sont traduits,
ainsi que l'espace insécable. Les autres caractères sont simplement
recopiés dans le flot de sortie courant.
| '<' {Html.put "<" ; main lexbuf}
| '>' {Html.put ">" ; main lexbuf}
| '~' {Html.put " " ; main lexbuf}
| _ {Html.put (lexeme lexbuf) ; main lexbuf}
(* (lexeme lexbuf) est le lexème~lu *)
Ce source illustre une première utilisation de la fonction
``lexeme'' qui, lorsqu'elle est appelée dans une action de
l'analyseur renvoie une chaîne contenant les caractères reconnus.
4.2 Mathématiques
Le principal défi de la traduction de LATEX vers HTML est posé
par les formules mathématique.
Il faut d'abord traduire les nombreux symboles mathématiques de
LATEX, comme par exemple ``\in'' à rendre par ``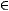 ''.
Pour ce faire,
HEVEA utilise une extension non-standard de HTML 3.2 implantée par
certains browsers (et en particulier les browsers Netscape récents) :
tout texte text compris dans l'élément
``
''.
Pour ce faire,
HEVEA utilise une extension non-standard de HTML 3.2 implantée par
certains browsers (et en particulier les browsers Netscape récents) :
tout texte text compris dans l'élément
``<FONT FACE=symbol>text</FONT>''
est affiché à l'aide d'une police de symboles qui comprend les lettres
grecques et les symboles mathématiques les plus courants.
Ainsi, le signe d'appartenance ``Î'' sera traduit en
``<FONT FACE=symbol>Î</FONT>'',
le code du caractère ``Î'' correspondant au signe ``Î''
dans la police de symboles.
(Le module Symb contient les définitions des
symboles rendus selon ce schéma, ces définitions sont mises à
disposition de l'analyseur principal par le module Macros.)
Ensuite, il faut pouvoir formater les formules mathématiques dont les
règles de composition s'éloignent sensiblement du modèle standard de
texte composé en paragraphes commun au mode paragraphe de LATEX et à HTML.
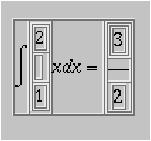
Par exemple la formule ``$$\int_1^2 xdx = \frac{3}{2}$$'',
à formater en mode « display math » est composée ainsi par
LATEX:
Les tables de HTML (c'est à dire, les éléments de niveau bloc
``<TABLE>...<\TABLE>'') offrent une
possibilité de contrôler le placement relatif par le browser.
HEVEAréalise le mode « display math » de LATEX
en ouvrant une telle
table,
les sous-formules étant ensuite arrangées en lignes et colonnes.
Ainsi, la formule ci-dessus sera rendue par HEVEA, puis par
Netscape communicator comme montré à la figure 2 (les bordures des tables qui servent au formatage
sont rendues visibles).
Figure 2 :
Composition d'une formule en mode
display
Les tables introduites par HEVEA pour la composition des formules
sont appelées « displays »
Il existe deux sortes de displays, les displays horizontaux qui sont des
tables d'une ligne et les displays verticaux qui sont des tables d'une
colonne.
Les cases des displays (colonnes dans le premier cas, lignes dans le
second) peuvent elles même contenir des displays.
Ainsi la formule de la figure 2 est constituée
d'un display horizontal à quatre cases dont la deuxième et la
quatrième sont des displays verticaux.
Remarquons que les colonnes des displays horizontaux sont centrées
verticalement et les
lignes des displays verticaux sont centrées horizontalement.
Le centrage des cases des displays peut être mis en défaut par
certaines formules déséquilibrées (par exemple une fraction avec un
numérateur et un dénominateur de tailles verticales très différentes),
toutefois la formule reste généralement compréhensible.
L'analyseur principal d'HEVEA utilise deux références booléenes
``in_math'' et ``display'' qui indiquent les modes
courants.
Commençons par examiner un effet du mode mathématique :
les caractères alphabétiques sont systématiquement mis en italiques
lorsque le mode mathématique est actif.
Pour ce faire, l'analyseur principal comprend la clause
suivante :
| ['a'-'z' 'A'-'Z']+
{let lxm = lexeme lexbuf in
if !in_math then begin
Html.put "<I>"; Html.put lxm; Html.put "</I>"
end else
Html.put lxm ;
main lexbuf}
Notons que les balises ``<I>'' et ``</I>'' sont ici émises
directement car on peut être sûr que ``lxm'' ne contient pas de
changement de style.
Remarquons aussi que cette clause est plus prioritaire que la clause par défaut
``| _ {...}'', de part la règle
classiques de reconnaissance des expressions régulières les plus longues
(« longuest match ») et parce que la clause
``['a'-'z''A'-'Z']+'' précède la clause par défaut dans le source
de l'analyseur.
Il est moins évident de détailler un exemple d'utilisation du mode
display.
Disons que de nombreuses constructions sont affectés par ce mode,
exposants, indices, grands symboles, fractions, etc.
Lorsque le mode display n'est pas actif, HEVEA génère uniquement
des éléments de niveau texte et donc ne génère pas d'élément
TABLE. En effet, les tables sont toujours
précédées et suivies d'un retour à la ligne lorsqu'elles sont
rendues par les browsers et leur introduction briserait la
continuité du texte.
Par exemple la formule
``$\int_1^2 xdx = \frac{3}{2}$'' placée dans le cours du texte
sera composé à l'aide des seuls éléments de niveau texte, ce qui donne :
<FONT FACE=symbol>ò</FONT>
<SUB><FONT SIZE=2>1</FONT></SUB><SUP><FONT SIZE=2>2</FONT></SUP>
<I>xdx</I> = 3/2
À comprendre comme suit :
4.3 Réalisation des modes mathématique et display
Cette section décrit en détail la réalisation des displays.
Dans un souci de simplification, seuls les displays horizontaux seront
abordés, on les désignera désormais simplement comme des
« displays ».
Le gestionnaire de sortie d'HEVEA fournit les fonction suivantes :
val open_display : unit -> unit
val close_display : unit -> unit
val item_display : unit -> unit
L'ouverture d'un display est essentiellement l'ouverture d'une
table (un bloc d'étiquette TABLE), d'une ligne (un bloc
TR) et d'une première case (un bloc TD).
La fermeture d'un display est donc la fermeture successive de trois
blocs, TD, TR et TABLE.
Enfin, la spécification d'une limite de case
(par item_display) est la fermeture d'un
bloc TD suivie de l'ouverture d'un nouveau bloc TD.
L'introduction des displays complique notablement la gestion des blocs.
En effet, l'ouverture (par Html.open_block) d'un bloc quelconque en
mode display
doit entraîner l'ouverture d'un display à l'intérieur du nouveau bloc,
display qui devra aussi être fermé avant de refermer ce bloc.
En effet, si tel n'était pas le cas, les balises
``</TD>'' et ``<TD>'' émises à l'occasion des limites de
cases seraient improprement placées à l'intérieur
de blocs quelconques et non pas dans un bloc TR.
Il faut également a priori émettre une limite de case avant l'ouverture
de bloc et après la fermeture de bloc,
afin d'assurer le centrage vertical d'éventuels displays verticaux
présents dans le bloc.
L'ouverture et la fermeture d'un bloc du gestionnaire de sortie
ne se feront donc plus directement, mais à l'aide des deux fonction
auxiliaires suivantes :
let top_open_block label args =
if !display then begin
Html.item_display () ;
Html.open_block label args ;
Html.open_display ()
end else
Html.open_block label args
and top_close_block label =
if !display then begin
Html.close_display () ;
Html.close_block label ;
Html.item_display ()
end else
Html.close_block label
Le mode mathématique est ouvert et refermé par le caractère
``$'' tandis que le mode « display maths »
est ouvert et fermé par le groupe de deux caractères ``$$''.
Par ailleurs, la construction ``\mbox{text}'',
formate toujours text en mode texte (c'est à dire non
mathématique et non display, même lorqu'elle
apparaît en mode mathématique ou display).
Néanmoins text peut contenir
des éléments à formater en mode mathématique ou display.
C'est à dire que l'on peut supposer que les trois constructions
précédentes sont arbitrairement imbricables (ce n'est pas tout à fait
le cas en LATEX, mais qui peut le plus peut le moins).
Les changements des variables d'état ``in_math'' et ``display''
sont donc gérés à l'aide
de deux piles ``math_stack'' et ``display_stack''.
En outre, il devient nécessaire lorsque l'on rencontre une accolade fermante
``}'' de savoir si elle ferme un ``{'' ou un ``\mbox{''
car, dans le second cas, il faudra éventuellement revenir en mode
mathématique.
Pour ce faire, l'analyseur principal maintient un environnement
courant ``cur_env'' et une pile ``stack_env'' des
environnements et groupes LATEX ouverts :
let open_env name =
push stack_env !cur_env ;
cur_env := name
and close_env name =
if name <> !cur_env then
failwith ("Fatal error in latex environments: "^
name^" closes "^ !cur_env) ;
cur_env := pop stack_env
Par convention, cur_env est la chaîne vide ``""''
dans un groupe ordinaire ``{...}'',
``"*math"'' dans un groupe mathématique
``$...$'' ou ``$$...$$'' et
``"*mbox"'' dans
``\mbox{...}''.
Examinons maintenant les reconnaissances
des débuts et fin de groupes mathématiques :
| '$' | "$$"
{let lxm = lexeme lexbuf in
if !in_math then begin
in_math := pop stack_math ; close_env "*math" ;
if lxm = "$" then
top_close_block ""
else begin
display := pop stack_display ;
Html.close_display () ; top_close_block "DIV"
end
end else begin
push stack_math !in_math ; in_math := true ;
if lxm = "$" then
top_open_block "" ""
else begin
top_open_block "DIV" "ALIGN=center" ;
push display_stack !display ; display := true ;
Html.open_display ()
end ;
open_env "*math"
end ;
main lexbuf}
On remarquera que ``in_math'' indique si l'on est en présence d'une
ouverture ou d'une fermeture et que
seule la gestion de ``display'' change
entre ``$'' et ``$$''.
En outre, les groupes ``$$...$$'' sont centrés comme en
LATEX.
Le cas de ``\mbox{'' est donné ci-dessous,
on notera que l'on n'utilise pas top_open_block
pour ouvrir le bloc, mais
directement Html.open_block :
| "\\mbox{"
{push math_stack !in_math ; in_math := false ;
if !display then Html.item_display () ;
push display_stack !display ; display := false
Html.open_block "" "" ;
open_env "*mbox" ;
main lexbuf}
Restent les clauses pour ``{'' et ``}'' qui remplacent
les clauses simplistes de la section 4.1 :
| '{' {top_open_block "" "" ; open_env "" ; main lexbuf}
| '}'
{if !cur_env = "*mbox" then begin
Html.close_block "" ;
in_math := pop stack_math ; display := pop display_stack ;
if !display then Html.item_display () ;
close_env "*mbox"
end else begin
top_close_block "" ;
close_env ""
end ;
main lexbuf}
On peut se convaincre que, sur un source LATEX correct, les
modes sont bien gérés : à chaque empilage d'une variable d'état lors
d'une ouverture de construction (``{'', ``$'', etc.)
correspond un dépilage de cette même
variable d'état lors de la fermeture de cette construction
(``}'', ``$'', etc.).
Mieux, les clauses précédentes permettent à d'autres constructions
LATEX bien parenthésées d'initier un passage en mode display,
par un code similaire à celui de ``$$''.
HEVEA procède effectivement de la sorte pour les tableaux (environnements
array et tabular) dont les éléments sont
systématiquement formatés en mode display, ce qui en améliore
sensiblement le rendu.
Dans la réalisation d'HEVEA, le gestionnaire de sortie s'efforce de
ne générer les displays et les limites de cases que lorsqu'elle sont
nécessaires : si le display fermé ne comprend qu'une case,
le contenu de cette case est simplement copié dans le canal de sortie
courant, les limites de cases ne sont réellement émises qu'autour des
cases contenant un display vertical, etc.
Ce genre de décision ne peut être prise qu'à la fermeture des displays
et des cases, le gestionnaire de sortie doit donc
identifier certains événements, comme l'émission effective d'un
display vertical.
Ces dispositions limitent grandement le nombre de tables émises
dans la sortie d'HEVEA.
Par exemple, on comparera
la figure 2 avec ce rendu de la même formule
sans les astuces :
On notera que le relatif coût de la recopie des tampons de sortie
trouve ici une compensation en terme de taille et de complexité du
HTML généré.
L'analyseur principal reconnaît d'autres constructions LATEX,
telles les tableaux, les listes, les exposants, les indices, les
délimiteurs (\left...\right) etc.
Je ne détaillerai pas la réalisation de ces constructions, qui
exploite largement les possibilités de retard, d'annulation et de
modification de l'émission du HTML par le gestionnaire de sortie.